In this post, we discuss the interesting paper by the late Steve Ross,”The Recovery Theorem”, in which a method is proposed to disentangle the risk aversion component from the subjective probability measure from state prices. In particular, a method is proposed to back out the market’s forecast of returns (a distribution over returns) from option prices.
Overview
State prices are the product of risk aversion—the pricing kernel—and the natural probability distribution. From derivatives prices we can observe distribution of state prices. The question then becomes: can we separate the markets probability distribution over returns and risk aversion? For example, we would like to know, given forward rates, how much of the rate is due to the market’s forecast and how much is a risk premium. In models with a representative agent, this is equivalent to knowing both the agent’s risk aversion and the agent’s subjective probability distribution, neither of which is observable but instead, inferred from calibrating market models.
Ross finds a decomposition of state prices into a risk adjustment and the natural probability distribution assuming that the pricing kernel is irreducible and transition independent (defined below). He calls this a recovery theorem. He proves his recovery theorem in two settings: finite state space, and a multinomial (potentially countably infinite) state space. The decomposition then allows us to express the market transition probabilities in terms of the stochastic discount factor and state prices, both of which can be estimated. The proof of the finite state space is essentially a fairly straight forward application of the Perron-Frobenius theorem. The proof of the result in the multinomial setting requires an additional assumption and follows from an unclear proof by (implicit) induction.
As a corollary to the recovery theorem, the subjective discount rate is shown to be bounded above by the largest interest factor. In addition, in the finite state case, if the riskless rate is state independent, then pricing is shown to be risk neutral. This is a very surprising result and in fact does not hold true for the countably infinite multinomial case. At the moment, I do not have good intuition for this result, but Ross claims that it is an artifact of having a finite irreducible process for a state transition (see bottom of pg 623).
Ross then goes on to demonstrate the recovery theory in two different ways. First, he shows for a “static” example, that given both the utility function (CRRA in his example) and the stock price distribution (lognormal) that using the recovery theorem, one can recover the natural probability measure using the pricing kernel (SDF) and the state prices. In the given example, the utility function and the price distribution are used to derive the expressions for the SDF and the state prices (through the Black-Scholes-Merton formula). He then calibrates the standard deviation and mean return of the price process (price distribution) to market data and shows that the resulting recovered transition probability distribution coincides with the lognormal distribution. This section (Section IV) proves to be deeper than just a verification of the theorem for an example. First, Ross points out that although the theorem was proven for the discrete and multinomial cases, it still seems to recover with a continuous distribution when considering a static problem (moving from one known initial state to an unknown state). However, once the dynamic problem is considered where one first transitions from a known state to an unknown state, then from the unknown state to another unknown state (from time 0 information set perspective), problems arise in that no implicit truncation of the distribution can be used. Details on this will be given below.
In section V, the recovery theorem is applied to the S&P 500 index to recover the market transition probabilities on April 27, 2011. What is remarkable about the recovery method is that it doesn’t need a training set. That is no historical data is explicitly needed to recover the distribution. The only place that Ross makes use of historical data is for the sake of comparison. Using historical returns, he constructs a bootstrapped histogram of returns and compares it to the recovered histogram of returns.
In the last section, a “model-free” test of the efficient market hypothesis (EMH) is proposed that essentially bounds the R^2 one can get from a factor model that would still be consistent with the EMH. Thus, any test of an investment strategy that uses publically available information and has the ability to predict future returns with R^2 > 10% would be a violation of efficient markets independent of the specific asset pricing model being used, subject to the maintained assumptions of the recovery theorem. Of course, such a strategy must also overcome transactions costs to really be a violation. His bound doesn’t take into account any transactions costs.
Basic Framework (§ II-III)
The basic framework is a discrete-time world with asset payoffs 
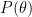
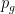

Where an asterisk denotes the expectation with respect to the martingale measure and where the pricing kernel, 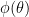




Our first assumption is that the asset value follows a Markov process. Ignoring the effects of the time value of money temporarily, the (martingale) transition density function, 

for any 



Taking back into account the time value of money, and making the second assumption that the process is time homogenous, the state price distribution is given by
![]()
Under the Markov assumption and assuming a continuous distribution for illustrative purposes, the kernel (state price per unit of probability (density)) as
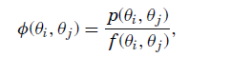
In the familiar world of a representative agent with additive time-separable preferences we get
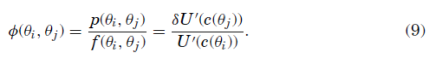
Most likely inspired by this form, Ross imposes the third assumption of transition independence on the kernel:

More general preferences than additive time-separable utility satisfy this form such as Epstein-Zin recursive preferences. At this point, we should pause to reflect how much this assumption has bought us. If we look at the LHS, in discrete time and state space world with m states, it will be a matrix with up to 
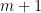


From (9) and (10) above, we obtain an expression for state prices
![]()
In what follows, we specialize our discussion to a discrete state space model. Let
![]()
where 


We can then express the natural transition matrix F as
![]()
In addition, since F is a transition matrix, its rows must sum to one, we have the additional set of m constraints:
![]()
Rearranging, we get the characteristic root problem:

Finally we make our fourth assumption that P is irreducible which allows us to use the Perron-Frobenius Theorem. One of the results of the theorem is that all non-negative irreducible matrices have a unique positive characteristic vector, z and associated eigenvalue 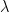

From this, we have that 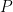
![]()
Furthermore, if the riskless rate is the same in all states, we get the surprising result

Multinomial Recovery (§ III)
Here Ross extends the theorem to an infinite horizon multinomial Lucus tree setting. It’s useful to note that three of the four sufficient conditions discussed hold in this setting. First, it is still a Markov process. Second, transition independence is directly assumed from assuming time additive utility set-up so that state prices will have the form of (10). Third, irreducibility still holds as any state almost surely is revisited in finite time. The assumption which is not met is the time independence assumption. The payoffs of the tree grow (or shrink) with time so it is another state variable. Under these assumptions we get Theorem 4:

An Example, Comments, and Extensions (§ IV)
In this section, Ross goes on to demonstrate the recovery theory in two different ways: first, he shows for a “static” example, that given both the utility function (CRRA in his example) and the stock price distribution (lognormal) that using the recovery theorem, one can recover the natural probability measure using the pricing kernel (SDF) and the state prices. In the given example, the utility function and the price distribution are used to derive the expressions for the SDF and the state prices (through the Black-Scholes-Merton formula). He then calibrates the standard deviation and mean return of the price process (price distribution) to market data and shows that the resulting recovered transition probability distribution coincides with the lognormal distribution. This section (Section IV) proves to be deeper than just a verification of the theorem for an example. First, Ross points out that although the theorem was proven for the discrete and multinomial cases, it still seems to recover with a continuous distribution when considering a static problem (moving from one known initial state to an unknown state). However, once the dynamic problem is considered where one first transitions from a known state to an unknown state, then from the unknown state to another unknown state (from time 0 information set perspective), problems arise in that no implicit truncation of the distribution can be used (see pg 632-633).
Applying the Recovery Theorem (§ V)
In this section, Ross relying on a rich market for European options to numerically approximate the state prices. To do so, we first note that a European call price with strike K and time of maturity T can be expressed as

From Breeden and Litzenberger (1978), and intuitively from naively applying the FTC, we have 
To apply the Recovery Theorem, we first have to estimate the

Now, to index the states, we think of there being m possible states at any time 0 and time T – there is no growth in this formulation as in the multinomial model. Ross’s notation in this section is pretty terrible, but for the sake of comparability with the paper I will maintain it and do my best to explain it. First, we denote each row of the transition matrix from time 0 to T, 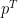

![]()
The arguments 


![]()
where m is the number of states. This is a system of 

Figure 2 show the recovered densities vs the bootstrapped ones. Ross points out that the recovered density has a fatter left tail and suggests that this provides support to the recovery method as we should expect the subjective density to have a fatter left tail (fear of disaster) than the actual probability density.
Testing the Efficient Market Hypothesis (§ VI)
In Ross (2005), an alternative test to testing the EMH by finding an upper bound to the volatility of the pricing kernel is proposed. The recovery method allows us to find a number for this upper bound. In particular, from the Hansen-Jagannathan bound there is a lower bound on the volatility of the pricing kernel, 
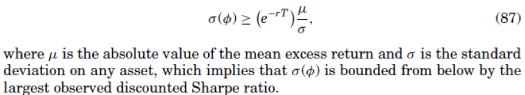
Recovery gives us an estimate 

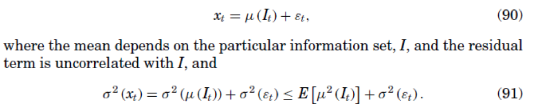
Rearranging and recalling (87) yields an upper bound on the 
![]()
Given the estimate of 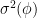
 on an open set
on an open set 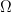 is meromorphic if there exists a discrete set of points
is meromorphic if there exists a discrete set of points  such that
such that  and has poles at each
and has poles at each 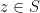 . Furthermore,
. Furthermore, 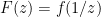 is either meromorphic or holomorphic at
is either meromorphic or holomorphic at  . In this case we say that
. In this case we say that  be the discrete set of singularities of a complex function
be the discrete set of singularities of a complex function 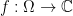 where
where 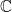 . For a fixed
. For a fixed 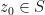 , suppose the Laurent expansion for
, suppose the Laurent expansion for  is given by
is given by  . Then,
. Then, 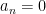 for all
for all 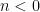 .
. 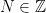 with
with  such that
such that 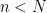 ; that is, the Laurent expansion of
; that is, the Laurent expansion of 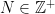 such that
such that  .
.
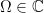 is an open set and
is an open set and  if there exists
if there exists 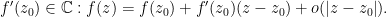 We say
We say 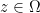 .
. with
with 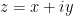 and
and 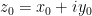 ,
, 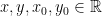 and write
and write 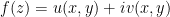 where
where  . Then,
. Then,![\displaystyle \left[ \begin{array}{cc} u(x,y) \\ v(x,y) \end{array} \right] = \left[ \begin{array}{cc} u(x_0, y_0) \\ v(x_0, y_0) \end{array} \right] + \left[ \begin{array}{cc} {\rm Re}f^{\prime}(z_{0}) & -{\rm Im}f^{\prime}(z_{0}) \\ {\rm Im}f^{\prime}(z_{0}) & {\rm Re}f^{\prime}(z_{0}) \end{array} \right] \left[ \begin{array}{cc} x-x_{0} \\ y-y_{0} \end{array} \right] + o(\left |x-x_{0}\right | + \left |y-y_{0}\right |).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+u%28x%2Cy%29+%5C%5C+v%28x%2Cy%29+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+u%28x_0%2C+y_0%29+%5C%5C+v%28x_0%2C+y_0%29+%5Cend%7Barray%7D+%5Cright%5D+%2B+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+%7B%5Crm+Re%7Df%5E%7B%5Cprime%7D%28z_%7B0%7D%29+%26+-%7B%5Crm+Im%7Df%5E%7B%5Cprime%7D%28z_%7B0%7D%29+%5C%5C+%7B%5Crm+Im%7Df%5E%7B%5Cprime%7D%28z_%7B0%7D%29+%26+%7B%5Crm+Re%7Df%5E%7B%5Cprime%7D%28z_%7B0%7D%29+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+x-x_%7B0%7D+%5C%5C+y-y_%7B0%7D+%5Cend%7Barray%7D+%5Cright%5D+%2B+o%28%5Cleft+%7Cx-x_%7B0%7D%5Cright+%7C+%2B+%5Cleft+%7Cy-y_%7B0%7D%5Cright+%7C%29.+&bg=FFFFFF&fg=000000&s=0&c=20201002)
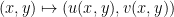 in
in 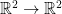 . In the real, multivariable case, the derivative of this map is a linear operator, namely, the Jacobian,
. In the real, multivariable case, the derivative of this map is a linear operator, namely, the Jacobian, 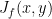 ; in our equation above, the
; in our equation above, the  matrix on the right hand side is
matrix on the right hand side is 